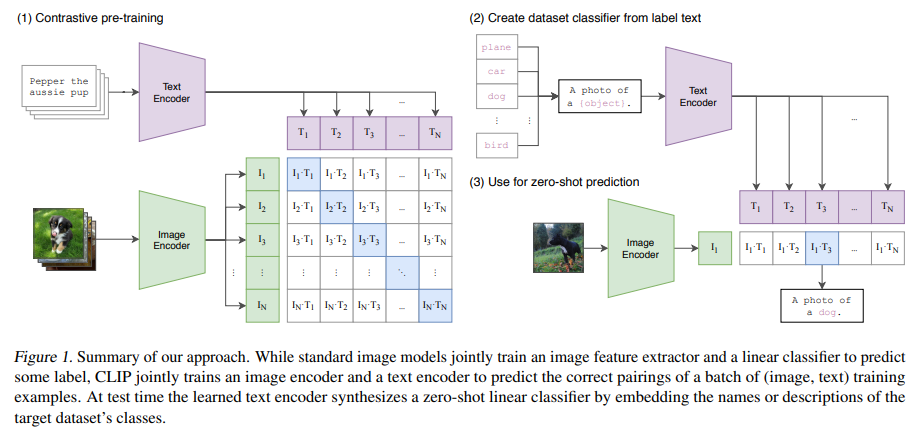
Abstractmachine이 생성한 instruction-following data를 사용한 instruction tuning LLM들은 새로운 task에서 zero-shot 성능 향상을 보여줌하지만, 이러한 아이디어는 멀티모달 분야에서는 덜 탐구됨본 연구는 language-only GPT-4를 사용하여 multimodal language-image instruction-following data를 생성하기 위한 첫 번째 시도를 제시이렇게 생성된 데이터에 대한 instruction tuning을 통해, 범용적인 visual and language 이해를 위한 vision encoder와 LLM을 연결한 end-to-end로 훈련된 large multimodal model인 LLaVA(Large Lang..