Abstract
- machine이 생성한 instruction-following data를 사용한 instruction tuning LLM들은 새로운 task에서 zero-shot 성능 향상을 보여줌
- 하지만, 이러한 아이디어는 멀티모달 분야에서는 덜 탐구됨
- 본 연구는 language-only GPT-4를 사용하여 multimodal language-image instruction-following data를 생성하기 위한 첫 번째 시도를 제시
- 이렇게 생성된 데이터에 대한 instruction tuning을 통해, 범용적인 visual and language 이해를 위한 vision encoder와 LLM을 연결한 end-to-end로 훈련된 large multimodal model인 LLaVA(Large Language and Vision Assistant)를 소개
- instruction-following data : 모델이 특정한 지시나 명령을 이해하고 따를 수 있도록 설계된 데이터.
- 이 데이터는 instruction(질문이나 요청)과 이에 대한 following(답변이나 설명)으로 구성되며 모델이 지시 사항에 맞춰 task를 수행할 수 있도록 훈련하는 데 사용.
- 이렇게 구성된 데이터는 모델이 다양한 유형의 질문이나 요청을 이해하고 요구사항을 충족하는 방식으로 답변하도록 훈련.
Introduction
- 멀티모달 vision-and-language instruction을 효과적으로 따르며 인간의 의도에 맞춰 다양한 real-world task를 수행할 수 있는 범용적인 assistant를 개발
- 본 연구에서는 visual instruction-tuning을 제안하는데, 이는 language-image multimodal 공간으로 instruction-tuning을 확장하려는 첫 번째 시도로, 범용적인 visual assistant를 구축하는 길을 열기 위함이다
- 한 가지 주요 과제는 vision-language instruction-following 데이터 부족
- 그래서 본 논문은 ChatGPT/GPT-4를 이용하여 image-text 쌍을 적절한 instruction-following 형식으로 변환하기 위한 데이터 재구성 관점 및 파이프라인을 제시
- CLIP의 visual encoder를 language decoder Vicuna와 연결하고 생성된 instructional vision-language data를 end-to-end로 fine-tuning하여 large multimodal model (LMM)을 개발
GPT-assisted Visual Instruction Data Generation
- multimodal instruction-following data에 있어서는 이용가능한 양이 제한적
- 최근 text-annotation task에서 GPT 모델들의 성공에 영감받아, 기존에 존재하는 image 쌍 데이터를 기반으로 multimodal instruction-following data 수집을 위해 ChatGPT/GPT-4를 활용할 것을 제안
- 기존 CC에서 LAION 같은 데이터셋은 단순한 Image 캡셔닝에 그침
- 그래서 LLaVA 를 학습하기 위한 instruction-following Dataset 생성이 필요
- 직접 작성 → cost 높은, human crowd-sourcing → 데이터 정의가 잘안됨.
Multimodal instruction-following Dataset 생성
- image $X_v$ 와 해당하는 Caption $X_c$ 가 있는 경우 이미지를 서술해 달라는 내용을 질문 $X_q$ 로한 데이터셋 생성
$$ \text{Human : } X_qX_v \text{ <STOP>} \text{Assistant : } X_c \text{ <STOP>} $$
- 하지만 다양성 부족 / 심도 있는 Reasoning 부족
- 이를 해결하기 위하여 GPT 사용
- ChatGPT/ GPT-4 가 visual content 를 이지 못함 → Symbolic Representations 으로 해결
- instruction-following Dataset 의 형태 → Conversation, Detailed description, Complex reasoning
Symbolic Representations

- language-only GPT-4 또는 ChatGPT 가 visual content를 포함한 instruction following 데이터를 생성하기 위해 화용
- Captions 을 시각적으로 다양한 관점에서 바라본 image Scence 에 대해 설명
- 즉 language-only 가 이해할수 있게 encode
- Bounding Boxes
- Scence 에서 특정 물체가 어디에 위치했는지 설명
instruction-following Dataset 의 형태
- Conversation : 이미지에 대해 질문하는 사람과 assistant 사이의 대화형식으로 디자인한다.
- 답변은 마치 assistant가 이미지를 보고 질문에 답하는 듯한 톤으로 되어있다. 객체 유형, 객체 수, 객체 동작, 객체 위치, 객체 간의 상대적 위치를 포함하여 이미지의 시각적 내용에 대해 다양한 질문을 한다. 명확한 답변이 있는 질문만 고려한다.
- Detailed description : 이미지에 대한 풍부하고 포괄적인 설명을 포함하기 위해 질문 목록을 만든다.
- 각 이미지에 대해 질문 목록에서 하나의 질문을 무작위로 샘플링하여 GPT-4에 상세한 설명을 생성하도록 요청한다.
- 답변은 일반적으로 엄격한 논리를 따르는 step-by-step reasoning process를 필요로한다.Complex reasoning : 위의 두 가지 유형은 content에 중점을 두며 이를 기반으로 심층 추론 질문을 추가로 생성한다.
Methodologies

Training
training data
- 각 image $X_v$ 에 대해 multi-turn conversation data $(X^1_q , X^1_a , · · · , X^T_q , X^T_a )$ 확보
- 각 conversation 의 답변을 assistant 의 답변으로 정의
- t 번째 instruction은 아래와 같이 지정
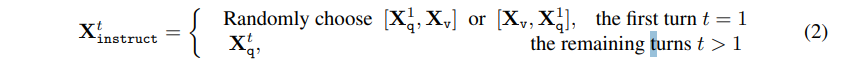

Stage 1: Pre-training for Feature Alignment
- image 에 대한 간ㄷ단한 요약을 요청하는 질문을 설정 후 GT 는 원 그림의 캡션으로 정의
- 이때는 linear 레이어만 학습함
- question Xq가 무작위로 샘플링되는데 이는 assistant에게 이미지를 간단히 설명하도록 요청하는 language instruction이다.
- ground-truth prediction answer Xa는 original caption이다. 학습에서, visual encoder와 LLM 가중치들을 frozen한 상태로 두고 학습 가능한 파라미터 θ = projection matrix W만을 사용하여 식 (3)의 likelihood를 최대화한다.
- 이렇게 함으로써 image feature Hv는 pre-trained LLM word embedding과 align된다. 이 stage는 frozen LLM에 대해 호환 가능한 visual tokenizer를 학습하는 것으로 이해할 수 있다.
Stage 2: Fine-tuning End-to-End
- visual encoder weight를 계속 frozen 상태로 유지하고 projection layer와 LLM의 사전학습된 가중치를 업데이트한다. 즉, 학습 가능한 파라미터 식 (3)에서 θ = {W, φ} 이다. 본 논문은 두 가지 특정 사례에 대해 고려
- Multimodal Chatbot : Section 3에서 설명된 158K language-image instruction-following data에 대해 chatbot을 finetuning하여 개발한다. 세 가지 유형중에서 conversation은 multi-turn 형식이고 나머지 두 개는 single-turn 형식이다. 학습 시 이들 응답 유형은 균일하게 샘플링된다.
- Science QA : ScienceQA benchmark에서 본 논문의 방법을 연구한다. ScienceQA는 상세한 강의와 설명으로 답변에 주석을 다는 최초의 대규모 multimodal science question dataset이다. 각 질문은 자연어 혹은 이미지 context로 제공되된다. assistant는 자연어로 추론 과정을 제공하고 객관식에서 대답을 선택한다. 식 (2)에서 학습 시, 데이터를 single turn conversation 형태로 구성하며, question & context를 Xinstruct로 reasoning & answer를 Xa로 설정한다.