Abstract
- 제한된 형태의 지도 학습은 다른 시각적 개념을 명시하기 위해 추가적인 레이블링된 데이터가 필요하기 때문에 일반성과 유용성을 제한함.
- 이미지에 대한 원시 텍스트로부터 직접 학습하는 것은 훨씬 더 광범위한 지도 학습 소스를 활용하는 유망한 대안
- 인터넷에서 수집된 4억 개의 (이미지, 텍스트) 쌍으로 구성된 데이터셋을 기반으로 어떤 캡션이 어떤 이미지에 속하는지 예측하는 간단한 사전 학습 작업이 SOTA 이미지 표현을 처음부터 학습하는 효율적
- 사전 학습 후, 자연어를 사용하여 학습된 visual concepts 을 참조하거나 새로운 개념을 설명함으로써 모델을 후속 작업으로 즉시 이전할 수 있음 (zero-shot transfer of the model to downstream tasks)
1. Introduction and Motivating Work
- Task-agnostic objectives such as autoregressive and masked language modeling have scaled across many orders of magnitude in compute, model capacity, and data, steadily improving capabilities
- 그러나 컴퓨터 비전과 같은 다른 분야에서는 ImageNet과 같은 crowd-labeled 데이터셋을 사용하여 모델을 사전 학습하는 것이 여전히 표준 관행
- 최근의 아키텍처와 사전 학습 방식을 채택한 VirTex, ICMLM 및 ConVIRT는 최근 transformer-based language modeling, masked language modeling 및 contrastive objectives 텍스트에서 이미지 표현을 학습하는 잠재력을 입증
- 본 연구에서는 이러한 차이를 줄이고 자연어 지도 학습을 통해 대규모로 학습된 이미지 분류기의 동작을 연구
- 인터넷에서 이러한 형태의 방대한 공개 데이터를 활용하여 4억 개의 (이미지, 텍스트) 쌍으로 구성된 새로운 데이터 세트를 생성하고, 처음부터 학습된 ConVIRT의 단순화된 버전인 CLIP(Contrastive Language-Image Pre-training)이 자연어 지도 학습을 위한 효율적인 방법임을 보여줌.
- 우리는 거의 두 자릿수의 연산량에 걸쳐 8개의 모델을 학습시켜 CLIP의 확장성을 연구했으며, 전이 성능이 연산 능력의 함수로서 원활하게 예측 가능함을 확인
- GPT 계열과 유사하게 CLIP은 사전 학습 과정에서 OCR, 지리적 위치 인식, 동작 인식 등 다양한 작업을 수행하도록 학습
2. Approach
2.1. Natural Language Supervision
- At the core of our approach is the idea of learning perception from supervision contained in natural language. → natural language supervision
- 초기 연구에서는 주제 모델과 n-gram 표현을 사용할 때 자연어의 복잡성을 해결해야 했지만, deep contextual representation learning 의 개선을 통해 이제는 풍부한 감독 소스를 효과적으로 활용할 수 있는 도구가 있음을 알 수 있음.
- 자연어 학습은 다른 학습 방법에 비해 여러 가지 잠재적인 장점을 가지고 있음.
- 이미지 분류를 위한 표준 크라우드소싱 레이블링에 비해 자연어 지도 학습을 확장하기가 훨씬 쉬움
- 자연어를 기반으로 하는 방법은 인터넷에 있는 방대한 양의 텍스트에 포함된 지도 학습을 통해 수동적으로 학습할 수 있음
- 자연어 학습은 대부분의 비지도 학습 또는 자기 지도 학습 방식보다 중요한 이점을 가지고 있는데, 단순히 표현을 학습하는 것이 아니라 해당 표현을 언어에 연결하여 유연한 제로샷 전이를 가능
2.2. Creating a Sufficiently Large Dataset
- natural language supervision 의 주요 동기는 인터넷에 공개적으로 이용 가능한 이러한 형태의 방대한 데이터이다.
- 인터넷에서 공개적으로 이용 가능한 다양한 출처에서 수집한 4억 개의 (이미지, 텍스트) 쌍으로 구성된 새로운 데이터셋을 구축
- To attempt to cover as broad a set of visual concepts as possible, we search for (image, text) pairs as part of the construction process whose text includes one of a set of 500,000 queries.
2.3. Selecting an Efficient Pre-Training Method
- VirTex와 유사한 초기 접근법은 이미지 CNN과 텍스트 변환기를 처음부터 공동 학습하여 이미지 캡션을 예측하는 것
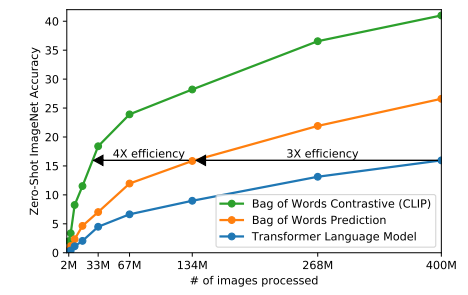
- 그림 2는 ResNet-50 이미지 인코더보다 두 배 더 많은 계산량을 사용하는 6,300만 개의 매개변수를 가진 변환기 언어 모델이 동일한 텍스트의 Bag-of-Words 인코딩을 예측하는 훨씬 더 간단한 기준선보다 세 배 더 느리게 ImageNet 클래스를 인식하는 것을 보여줌
- Both these approaches share a key similarity → 각 이미지에 수반되는 텍스트의 정확한 단어를 예측하려고 시도
- 이는 이미지와 함께 나타나는 다양한 설명, 주석 및 관련 텍스트로 인해 어려운 작업
- 이미지에 대한 contrastive representation learning 에 대한 최근 연구에서는 contrastive objectives 가 equivalent predictive objective 보다 더 나은 표현을 학습할 수 있음을 발견
- we explored training a system to solve the potentially easier proxy task of predicting only which text as a whole is paired with which image and not the exact words of that text.
- 동일한 단어 묶음 인코딩 기준선을 시작으로, 그림 2에서 예측 목적을 대조 목적으로 바꾸었고 ImageNet으로의 제로샷 전송 속도에서 효율성이 4배 더 향상되는 것을 관찰
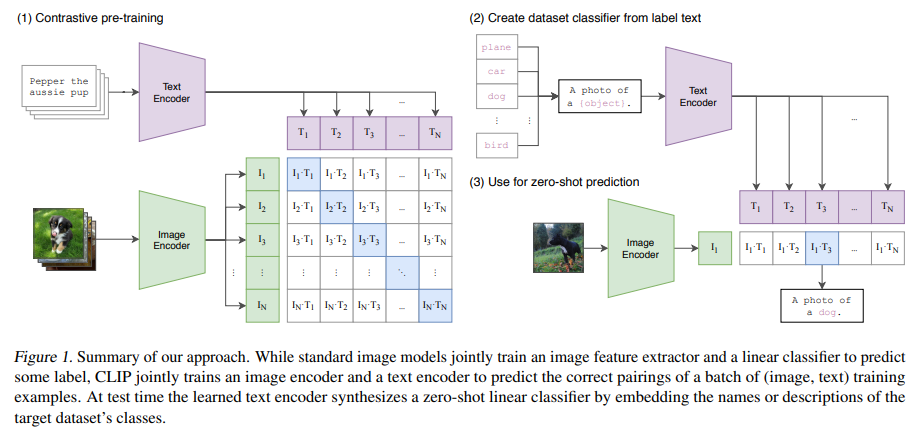
- N개의 (이미지, 텍스트) 쌍으로 구성된 배치가 주어지면, CLIP은 배치 전체에서 가능한 N × N개의 (이미지, 텍스트) 쌍 중 실제로 발생한 쌍을 예측하도록 학습
- 이를 위해 CLIP은 이미지 인코더와 텍스트 인코더를 공동으로 학습하여 배치 내 N개의 실수 쌍의 이미지 및 텍스트 임베딩의 코사인 유사도를 최대화하는 동시에 $N^2 - N$ 개의 잘못된 쌍의 임베딩의 코사인 유사도를 최소화함으로써 다중 모달 임베딩 공간을 학습
- 이러한 유사도 점수에 대한 대칭적 교차 엔트로피 손실을 최적화

- mageNet 가중치로 이미지 인코더를 초기화하거나 사전 학습된 가중치로 텍스트 인코더를 초기화하지 않고 처음부터 CLIP을 학습
- 표현과 대조 임베딩 공간 사이의 비선형 투영을 사용하지 않음
- 대신 각 인코더의 표현에서 다중 모달 임베딩 공간으로 매핑하기 위해 선형 투영만 사용
- 이미지 transformation function 을 단순화
- 학습 과정에서는 크기가 조정된 이미지에서 무작위로 정사각형을 잘라내는 것만 데이터 증강에 사용
- 소프트맥스에서 로짓의 범위를 제어하는 temperature parameter τ는 하이퍼파라미터로 변환되는 것을 방지하기 위해 학습 과정에서 log-parameterized multiplicative scalar 로 직접 최적화
2.4. Choosing and Scaling a Model
- 이미지 인코더를 위해 두 가지 아키텍처를 고려
- 첫 번째 아키텍처는 널리 채택되고 성능이 검증된 ResNet-50
- 두 번째 아키텍처에서는 최근 도입된 비전 트랜스포머(Vision Transformer, ViT)(Dosovitskiy et al., 2020)를 실험
- 텍스트 인코더는 Radford et al.(2019)에서 설명한 아키텍처 수정을 적용한 Transformer
- 기본 크기로 8개의 어텐션 헤드가 있는 63M 매개변수 12계층 512폭 모델을 사용
- Transformer는 49,152개의 어휘 크기를 갖는 텍스트의 소문자 바이트 쌍 인코딩(BPE) 표현에서 작동
- 계산 효율성을 위해 최대 시퀀스 길이는 76으로 제한
- 텍스트 시퀀스는 [SOS] 및 [EOS] 토큰으로 괄호로 묶이고 [EOS] 토큰에서 Transformer의 최상위 계층의 활성화는 계층 정규화된 다음 다중 모달 임베딩 공간으로 선형 투영되는 텍스트의 특징 표현으로 처리
- 사전 훈련된 언어 모델로 초기화하거나 언어 모델링을 보조 목표로 추가하는 기능을 유지하기 위해 텍스트 인코더에서 마스크된 자기 주의가 사용되었지만, 이에 대한 탐구는 향후 작업으로 남겨둠.
3. 실험
- 여기서는 그냥 좋은 아이디어를 정리하면
- embedding ensemble
- Prompt engineering (up acc)